AI 2026: Bubble or Breakout? Where the Real Value Is Being Created

The NASDAQ is at all-time highs driven by AI-fueled stocks, many exceeding trillion-dollar valuations. OpenAI and Anthropic are racing to IPO. U.S. companies are on track to spend nearly $400B on AI infrastructure this year (up from ~$190B in 2024). Conservative estimates put the total collective expenditure by 2030 at $5 trillion. By 2030, annual energy consumption from AI data centers is projected to exceed 500 TWh, roughly France’s total electricity use. Meanwhile, headline valuations — across hyperscalers, model labs, and venture-backed startups —continue to climb. We’re clearly in the middle of the generative-AI revolution. The harder question: are we in a bubble?
A bubble is typically when prices run far ahead of intrinsic value, driven by speculation and herd behavior rather than fundamentals. So, to answer the question, we need to separate signal from noise: what works, what doesn’t, and what reasonably could. And, most importantly, where is the revenue?
A Little History
It has been just over 5 years since the launch of GPT-3, which was the true, early turning point towards the current Generative AI era. We started with 1 model and 1 model provider, but even then the implications were huge.
| Mid 2020: | GPT 3 launches; huge but niche enthusiasm and development; mainly text and email content generation |
| Mid 2021: | Startups like Jasper AI launch; height of the general economic market bubble |
| Mid 2022: | Amidst a broader market correction, GPT 3.5 launched and was insanely better than GPT 3; laid the foundation for ChatGPT w/instruction following, conversation-focused fine-tuning |
| Late 2022: | ChatGPT launched in what I call AI's "wow moment"; clear turning point; the world woke up to AI's potential |
| Early 2023: | Meta's Llama 1 and Anthropic Claude 1 launched in limited release; a huge influx of almost indiscriminate venture capital flowed into startups of all kinds that claimed "AI," leading to the "AI Spring." |
| Mid 2023: | • Google Gemini 1 launched; • Companies like Jasper took valuation write-downs; expressions like "thin-wrapper on GPT" came into existence. |
| Early 2024: | • "Data exhaustion" problem: models hit a ceiling hit in available training data • Emergence of early, open-source agentic platforms • Gen AI entered a mini anti-hype cycle as investors worried that all value would accrue to the model labs |
| Late 2024: | OpenAI releases o1 - first ever "reasoning model"; major step-change |
| Early 2025: | • DeepSeek released models and a Chat-GPT-like app they claimed were trained for a tiny fraction of OpenAI budget; market concerns over model commoditization • All major labs release reasoning models |
| Mid 2025: | • OpenAI, Google and Meta release first agentic platforms • Rise of reasoning models: shifts compute to test-time • Data Exhaustion solved as models can generate their own high-quality training data by reasoning • It is clear that AI models are continuing to improve at exponential pace; major labs are able to copy each other within months |
| Late 2025: | • Google finally leapfrogs the market with a SOTA model for image gen • OpenAI, Anthropic talk about massive IPOs as early as 2026 • All labs and partners announce massive capex plans to invest in AI infrastructure |
What is Now Clear…
While there is still a lot of noise, 3 things have, in fact, gotten much clearer to us over the last few years:
- Foundation models work, have standardized, and demand exponential data + compute.
- Intelligence will come in layers: today it is shifting from knowledge to action, i.e. Agents.
- Two new, massive application markets have materialized — and there is more to come
1. Foundation Models are the standard and have consolidated:
The Formula for Manufacturing Intelligence
A foundation model is a large, general-purpose system trained on diverse data, then adapted for downstream tasks. While LLMs dominate the conversation, today’s leading foundation models are multimodal (handling text, images, audio, video and increasingly scientific data in chemistry, biology, and materials).
Regardless of where we are on a path to AGI, it is indisputable that today’s foundation models “work.” Across broad tasks, today’s models produce quantifiable, human-adjacent intelligence at price points that make mass global distribution viable. Even if progress paused, there’s billions in unlocked GDP from current deployment alone.
Moreover, it is clear that there is still tremendous opportunity to make these models even smarter. Today, the rough formula to do this is:
- Pre-training: Use transformer-based architecture and train on massive general datasets to learn general world representations (next-token prediction).
- Post-training: Run large-scale reinforcement-learning (Chain-of-Thought, reasoning traces, reflection and critique loops, etc.) that teaches the model how to generate intermediate reasoning steps before deriving a final answer, i.e. “reasoning.” Can also include fine-tuning, Retrieval Augmented Generation (RAG), Reinforcement Learning with Human Feedback (RLHF) and other techniques to make the model task-/domain-specific, and more accurate, usable and/or safer
- Deployment iteration: deploy model in an actual use case or application, where the model is interacting with users, using tools and solving real-time problems, potentially outside its direct training;
- Continuous learning: Keep model current, extend capability, enhance safety
The main inputs to this formula are data and compute - more leads to “bigger, smarter models.” So, training compute is doubling every ~5 months and data every ~8 months. Improvements in model architecture, algorithms and/or hardware optimization also contribute, but this tends to merely shift the curve vs. reduce spending. For example, if the innovation is a 2x "compute multiplier", it may allow a 40% improvement on a coding task for $5M instead of $10M. But because the value of having a more intelligent system is so high today, the gains in cost efficiency usually end up entirely devoted to training smarter models, limited only by the company's financial resources.
Industry / Platform Consolidation
Staying ahead demands immense capital and very specialized and unique talent. There are still only a handful of people in the world who really know how to do this… In fact, since 2018, less than 100 companies have built ~250+ foundation models across corporate, academic, and open-source ecosystems, which is not a lot, given the scale and enormity of the opportunity.
As such, the playing field has consolidated and stabilized in the last 5 years. The key players are Anthropic, OpenAI, Google, Meta, Microsoft, and xAI. They are often tightly coupled with the major cloud hyperscalers: Anthropic with AWS and Google, OpenAI with Microsoft Azure, and Google with its own Google Cloud Platform (GCP). These alliances are blurring, though, and most cloud providers have alliances with multiple labs. And everyone is dependent on the chip providers – Nvidia, AMD - though most of the labs and cloud providers are also designing and developing their own chips. This has led many to worry about not just the extreme concentration of capital and talent, but also the complicated web of potentially “circular financing.”
Extremely well-funded Chinese labs like Deepseek, Alibaba and MoonShot AI are also muscling into the limelight. But these companies are generally following the American model of high capital, scale and concentrated talent. They do however, tend to open source and make it cheaper to run but must keep up on capabilities.
In our view, it is clear, given the current “formula” for manufacturing intelligence, that there is no real way around this infrastructure buildout.
In some ways, it is much like the 1990s internet buildout that laid the foundation for mainstream adoption later. Some have used the analogy of the great railroad buildout of the 1800s, which may be more apt. Either way, ee did see a spectacular “dot-com bust” in 2001 and there was a period of oversupply in railroads. Will it be any different here?
What’s Different
A few elements differentiate current events:
- Sources of funding: While debt is certainly a source, in general, Big Tech is using cash from their own balance sheets to finance these activities, not leverage. In the case of the Mag7, this cash comes from massively profitable operating businesses. The private AI companies are using equity, but the financiers are often deep pockets of private wealth or sovereign wealth funds. A massive correction will certainly impact everyone, but it will actually disproportionately affect the “generationally wealthy” who have very long time horizons. This may change in 2026 / 2027 but is significantly different than past “boom / busts.”
- Revenue: Unlike previous eras, we ****are already seeing massive revenue and revenue potential in the applications for which all this intelligence is being built. A quick analysis of just the big labs and public software companies indicated an annualized total of $100-120BN for 2025. This does NOT include infrastructure (chips, datacenters etc) as the point is to figure out whether the spend on that infra is yielding actual revenue for other companies. This probably underestimates by 10-20% total AI application revenue today as it does not account for any private startups other than Anthropic.
Of course, you need to believe way more in the revenue potential than current revenue to justify the infrastructure append. Some analysis indicates that OpenAI would have to grow from ~$20BN of projected revenue in 2025 to $577BN by 2029, roughly the size of Google’s revenue in the same year, to justify the ~$1TN it will spend in infrastructure (OpenAI is currently projecting $100BN in revenue by 2027). This will have to come from its own applications but also from the use of its models for other companies’ applications.
So, the real question is what’s next, i.e. where are these models actually taking us?
2. Layers of Intelligence: From Knowledge to Action i.e. Agentic AI
Foundation models are necessary to this new AI revolution, but not sufficient to justify all the spend and hype. In a sense, they are the first layer – or building block – in the intelligence stack.
The next interesting “layer” is agentic AI: autonomous, goal-directed systems that plan, act, and adapt with minimal supervision, often by orchestrating multiple tools and sub-agents. Breakthroughs in methods like chain-of-thought and reasoning capability over the last year enable models to decompose tasks, plan, reflect, and self-correct across multi-step objectives (vs just single-shot text generation).
These massive developments are being driven by both the large foundation model providers and smaller startups. The tools and platforms they are building are starting to democratize agent creation and inspire novel applications by developers. In fact, every single Axiom portfolio company – each of which aims to generate half a billion in revenue over the next 10years – uses cutting edge agentic AI to build insanely useful and usable new products. And, there are hundreds of other high potential startups doing the same.
The result? The products these companies are building look more like the work that humans do vs. the software tools that they use. These AI systems are solving problems and getting real work done for us. Historically, software augmented humans. Now, it’s doing human work.
That changes everything.
I first wrote about this potential application of AI in May 2024. Today, we are seeing this innovation in action. For example, in our own portfolio, we have JuliusAI who is building an AI Data Scientist. They are not building software that automates workflows for data scientists. Rather, they are building an autonomous data scientist. There are only ~3M data scientists in the world but we believe that the demand for this capability could be 1-2 orders of magnitude higher. This unlocks a brand new TAM that is outside the current B2B software market, in which Julius can command ASPs that look more like several hundred thousand dollars per data scientist hired vs $20-80 /month for a software tool.
Some have estimated the market opportunity for these “agentic applications” to be on the order of magnitude of net-new $10TN+:
- Labor budgets are 10x larger than software budgets; companies need to hire
- Many legacy industries have hidden, untapped margin and are untapped or under-digitized
- Few (if any) dominant incumbents.
Agentic AI changes software from a reactive API layer to a proactive operating layer. The broad horizontal platforms are still early, but they preview entirely new categories of applications. And, $10TN in new revenue would certainly justify all this infrastructure spend!
3. Two 2 new, massive application markets have materialized: Coding and Search
The next “intelligence layer” will be the applications that are built with agentic AI. We believe that there will be hundreds - of new markets created. To date, 2 markets have already evolved at scale: Coding and Search. Despite being the two obvious and early markets that would benefit from AI, it was brand new startups that caused the disruption - and large model providers that are paying big bucks to acquire or compete.
- Coding AI Coding assistants have moved from novelty to daily tooling in ~4 years. Early traction came from Microsoft GitHub Copilot (powered by OpenAI), but startups like Cursor and Windsurf demonstrated strong product velocity and adoption, and moved ahead of incumbents in terms of traction and revenue. Cursor remains an independent, fast-growing company with a reported $1BN ARR, but both Cognition (~$155M ARR) and Google have acquired parts of Windsurf. And now, “Vibe coding” and visual/agentic paradigms (e.g., Replit ~($150M ARR), Lovable (~$200M ARR)) point to new workflows and user segments. While there is still room to innovate, the inability of many players to have positive gross margins and/or GTM profitably is a key current problem and the newer players are starting to train their own models to bring down costs. The category will likely consolidate around players with distribution, cost advantage, or unique workflows, but it has already been an excellent market for early venture and shows how quickly AI markets can scale.
- Search: For the first time in two decades, search is being re-written, thanks to AI. Generative systems augment retrieval with conversational answers, reasoning, and task assistance, going well beyond “10 blue links.” Leading the disruption is actually a startup called Perplexity.ai, already valued at $18BN with a reported $200M ARR. OpenAI and Anthropic now integrate search into conversational experiences and Microsoft and Google embed conversational AI directly into their Search. Monetization remains an open question with “direct-answer UX” reducing clicks to sites. But this pressure on traditional ad models and SEO is actually the real disruptive force and key driver of new revenue opportunities. We expect to see new companies that figure this out well to scale rapidly and emulate the AI coding market - with perhaps even bigger outcomes.
- Other early markets According to OpenAI, technology, healthcare and manufacturing showed the highest growth in AI adoption (as measured by messages sent across their models and ChatGPT). But there is deep penetration in Finance and Professional Services, with emergent usage in Construction, Entertainment and Education.
AI adoption by industry: enterprise scale vs. year-over-year growth
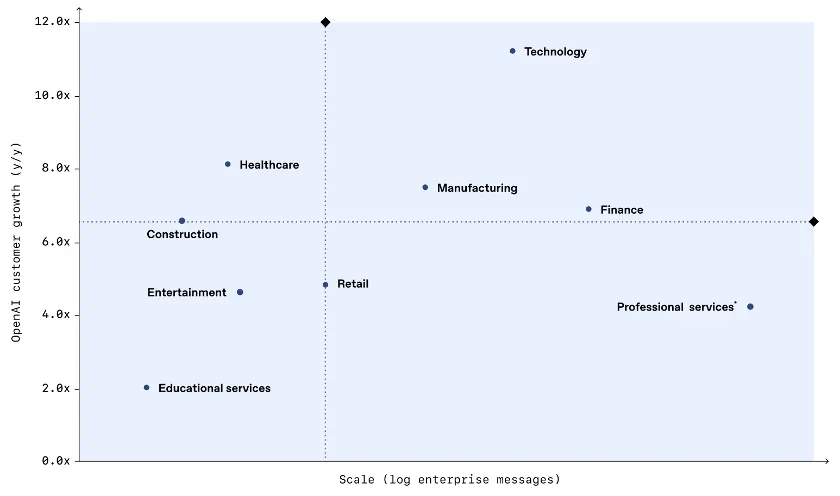
Source: OpenAI
We are also already seeing “AI-native” startups in many of these sectors who have scaled to meaningful revenue including:
- Glean, Enterprise Search: ~$200M ARR
- ElevenLabs, AI Voice: ~$200M
- HarveyAI, Legal: ~$100M ARR
- Sierra, Customer Service: $100M ARR
The breadth of adoption of AI across industries is unprecedented for a new technology, especially so early in the technology cycle.Value is accruing to both model providers and focused application companies. And we’re still very early …
Investment Implications
The Bull Case
So, are we in a bubble? The answer is, of course, nuanced.
On one hand, the warning signs are real. Valuations have skyrocketed, capital deployment is reaching unprecedented levels, and the infrastructure spend requires heroic assumptions about future revenue growth. The comparison to historical bubbles, from railroads to dot-com, isn't unfounded.
But on the other hand, this moment feels fundamentally different. It is always dangerous to say “this time is different,” but a few things are clear:
- the technology demonstrably works and continues to improve at an exponential pace.
- we're already seeing substantial revenue materialization outside the infrastructure and models — over $100 billion annually and growing.
- the funding sources are more stable, coming from profitable tech giants' balance sheets rather than overleveraged debt.
At peak, the internet contributed ~1.35% to annual U.S. GDP growth. Recent estimates put AI’s contribution at ~0.85% and rising. Even if AI “only” matches the internet’s scale, there’s room to run.
The figure below shows where we believe that “room to run” will come from. We see 3 distinct layers of how we are building intelligence:
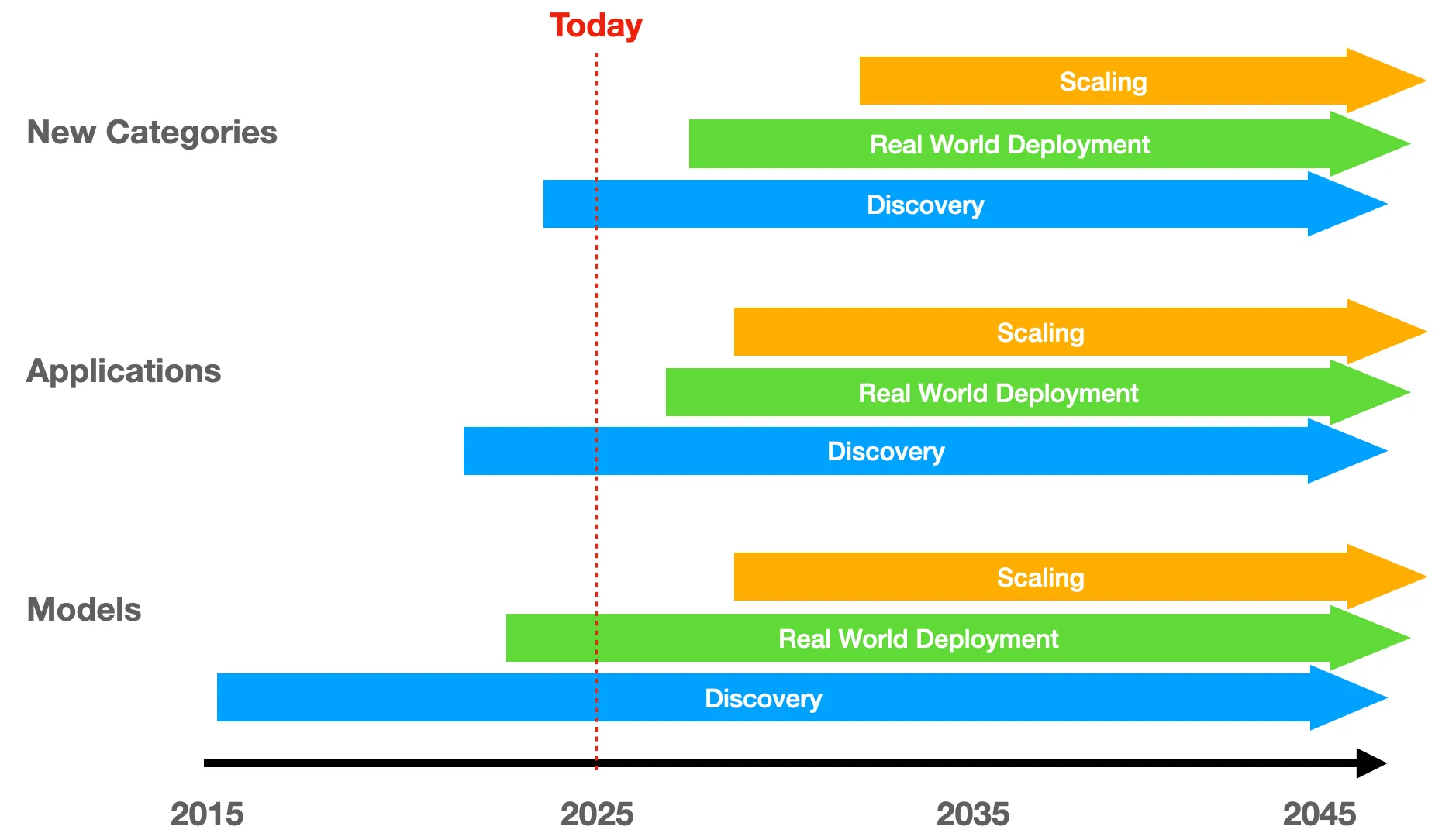
- The Model layer has consolidated around a small group of well-capitalized players who will continue their arms race of data and compute. Innovation will continue but this is the most “obvious” layer, implying that it is already fully valued.
- New innovation and value creation is happening in the Application layer, where hundreds of startups are building AI-native products across every industry imaginable. The breadth of adoption we're seeing, from healthcare to manufacturing to entertainment, is unprecedented for such an early-stage technology. This is an area rife with opportunity but there will also be many “me-too” apps. Be discerning.
- Most importantly, we're witnessing the emergence of entirely New Categories. The shift from knowledge-based AI to agentic, action-oriented systems promises to unlock a potential $10 trillion opportunity that comes from automating labor rather than just augmenting software tools. We believe the greatest outlier returns will come from this intelligence layer.
In each of these layers, there are phases:
- Discovery: the period of early exploration and experimentation that leads to breakthrough innovation
- Real World Deployment: enough stability in underlying technology to implement with customers and get initial value proof points
- Scaling: mass deployment and value creation
I would argue that we are just entering the Real World Deployment phase of Models. This is where the rubber meets the road and there will be some days of reckoning ahead. This doesn’t mean that new innovation won’t continue to occur. In fact, there may be a step-change that leads to a new Discovery phase in the future. But for now, we have a “formula” and the goal is to get rapid, profitable and useful deployment of Models in a broad based way.
We are likely still in the Discovery phase for Applications and New Categories, but they are happening almost simultaneously and may progress more quickly as there is less engineering and capex investment required upfront.
Regardless, this more nuanced, time-based lens shows just how early we are in this new AI paradigm shift.
The Risk Vectors
There are 3 major risk themes could interrupt the overall macro trends discussed above, and cause a major market meltdown.
- We are satisfied with less: Society deems “good enough” intelligence sufficient, and slows investment in further capabilities
- A new paradigm leapfrogs the stack: A completely new architecture or training regime delivers intelligence without today’s data/compute intensity, resetting cost and investment curves.
- Innovation becomes too highly concentrated: If a leading lab stalls on innovation, governance, or capital, progress could decelerate dramatically and have a broad ripple effect.
We believe that #1 is unlikely and that #2 is possible but still low probability. #3 has the highest probability but would also be the most short-term and lowest magnitude of disruption, given how competitive the market is today.
Investment Implications
- Be a stock picker, not an indexer. This wave will mint outsized winners and produce spectacular failures. Don’t “AI-ETF” your way through it.
- Look around the next corner. The obvious trades are already fully priced. Hunt for new category creation where AI is a first-class actor.
- Match horizon to physics. The infra and capability cycles run in multi-year arcs. Set timeframes and base-rate returns accordingly; avoid having to time the exact top in names like Nvidia or the frontier labs.